Patrick Hoey's Blog
Web Scraper
I have used my experience creating back-end enterprise services to create a web scraper over a weekend. I used a data access object design pattern for the SQL DB layer. I also created a service to persist the word frequency values based on the different websites accessed. I documented the process as if I was communicating with a prospective client.
Languages: Java
Platforms: Windows 7
Environment: Eclipse IDE, Git, MySQL, Maven
Libraries: JSoup
Source: GitHub Link
Application Specification
A java application that accepts a URL, and crawls the page that the URL references. Determine all the words that aren’t part of the HTML on the page and the frequency counts for each with the results stored in a database.
Research
There are many factors to consider depending on whether we want to grow our own proprietary web scraping tool or use an existing one. The question is whether this is something we would want to maintain in the long-term as a valid add to the business. If we were to develop our own, there would be a heavy reliance on regular expressions, and as a web service, we would utilize the JEE libraries for enterprise development to help with scalability.
Maybe in the future we want to license out the use of a web server version of this for clients.
The following table (Figure 1) lists some options for third party support of web content extraction:
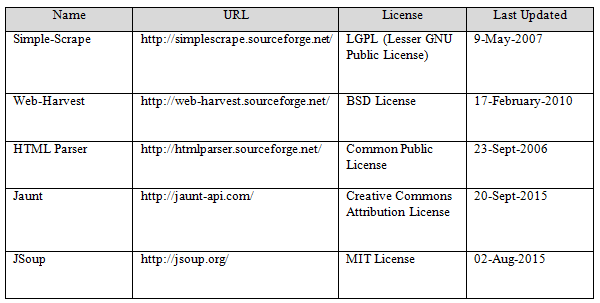
Figure 1
We could start will a relatively recent web scraper first that has a license where we can update as we please, without needing to expose our internal code or pay a royalty. Most of the technologies listed are defunct, with a few still currently maintained. Out of all the choices, after brief research, JSoup seems to be the best option (with limited time for this project) based on the following criteria:
- Free
- MIT License
- Source available on GitHub
- Actively Maintained
- Relatively mature codebase
- Simple interface with a sophisticated parser
- Lightweight (no external dependencies)
If we want, as we update the source of the third party with fixes and features, we may want to issue pull requests on the existing third party library so that they can integrate our changes to their main trunk.
Legal Pitfalls
This is a just a quick note that web scraping is considered a legal grey area even though there is no definitive case law or statutes on the subject. Some providers maintain their robots.txt file to give instructions about their site to web crawling bots. This is called The Robots Exclusion Protocol. In reality, most of the time the robots.txt file is ignored. This behavior could be considered a violation of the Terms of Service (ToS) for the websites which can lead to possible action taken by the providers.
Environment
The following list represents all of the tools and third party libraries that I used for this project.
- Hardware: Acer Aspire V3-771 laptop; 8 GB of RAM; Intel i7 2.2Ghz (8 cores)
- OS: Windows 7 Home Premium Edition (64 bit)
- IDE: Eclipse IDE for Java EE Developers (Mars 1 release)
- DB: MySQL Community Server (GPL) v5.7.9; Needed Visual C++ Redistributable Package Visual Studio 2013 (64bit); Python 3.4.3
- VCS: Git v1.9.4; SmartGit v7.0.3
- Build: Maven
- Third Party Libraries:
- JSoup v1.8.3
- MySQL-Connector-Java v5.1.37
- Java Version: Java SE Development Kit 8u66
Data Model
I used MySQL Workbench to create the following data model (Figure 2):

Figure 2
The ExtractionJobTable table represents all of the jobs that need to be processed by the ExtractionService (discussed in the next section). There are four columns in the ExtractionJobTable table: idExtractJobTable, extractJobDateTime, extractJobURL, and IsProcessed. The idExtractJobTable column has a data type of an unsigned INT with auto incrementing because this column represents the primary key for this table. The extractJobDateTime column has a data type of DATETIME to represent the date and time that this particular record was added. This acts as an audit trail to determine why certain jobs failed or to sort them by priority based on recently added. The extractJobURL column has a data type of TEXT which represents the URL to be processed by the extraction service and should be able to accommodate any URL length (2^16-1 bytes or 64 KB). The IsProcessed column has a date type of TINYINT(1) to represent either this job has been processed (TRUE) or not (FALSE).
The ExtractionTable table represents all of the records created by the ExtractionService (discussed in the next section) that has the extracted text scraped from the URL. There are four columns in the ExtractionTable table: idExtractionTable, extractionDateTime, extractionURL, and extractionText. The idExtractionTable column has a data type of an unsigned INT with auto incrementing because this column represents the primary key for this table. The extractionDateTime column has a data type of DATETIME to represent the date and time that this particular record was added. This acts as an audit trail to determine why certain jobs failed or to sort them by priority based on recently added. The extractionURL column has a data type of TEXT which represents the URL to be processed by the extraction service and should be able to accommodate any URL length (2^16-1 bytes or 64 KB). The reason we do not have a foreign key here is because the ExtractionJobTable jobs are transient and can be deleted at any time. The extractionText column has a data type of LONGTEXT which should be sufficient to cover most data extraction as LONGTEXT represents a length of 2^32-1 bytes or 4 GB.
The ParseJobTable table represents all of the jobs that need to be processed by the ParsingService (discussed in the next section). There are four columns in the ParseJobTable table: idParseJobTable, parseJobDateTime, extractionTableID, and IsProcessed. The idParseJobTable column has a data type of an unsigned INT with auto incrementing because this column represents the primary key for this table. The parseJobDateTime column has a data type of DATETIME to represent the date and time that this particular record was added. This acts as an audit trail to determine why certain jobs failed or to sort them by priority based on recently added. The extractionTableID column has a data type of an unsigned INT, a foreign key which maps to a primary key in the ExtractionTable table. The IsProcessed column has a date type of TINYINT(1) to represent either this job has been processed (TRUE) or not (FALSE).
The WordFrequencyTable table represents all of the records created by the ParsingService (discussed in the next section) that contain the tokenized words with their frequencies. There are four columns in the WordFrequencyTable table: idWordFrequency, word, lastUpdatedDateTime, and frequency. The idWordFrequency column has a data type of an unsigned INT with auto incrementing because this column represents the primary key for this table. The word column has a data type of VARCHAR(255) which represents the word that was processed by the parsing service. Unfortunately, this is the largest data type that is supported with a unique constraint. The lastUpdatedDateTime column has a data type of DATETIME to represent the date and time that this particular record was added or updated. This acts as an audit trail to determine why certain jobs failed or to sort them by priority based on recently added. The frequency column has a data type of INT which represents the total number of times that a particular value in the word column was parsed from a URL extraction.
Now that we have a better understanding of the data model in the database, we can now discuss the object model in how the DB is accessed and updated starting with the following Figure 3:
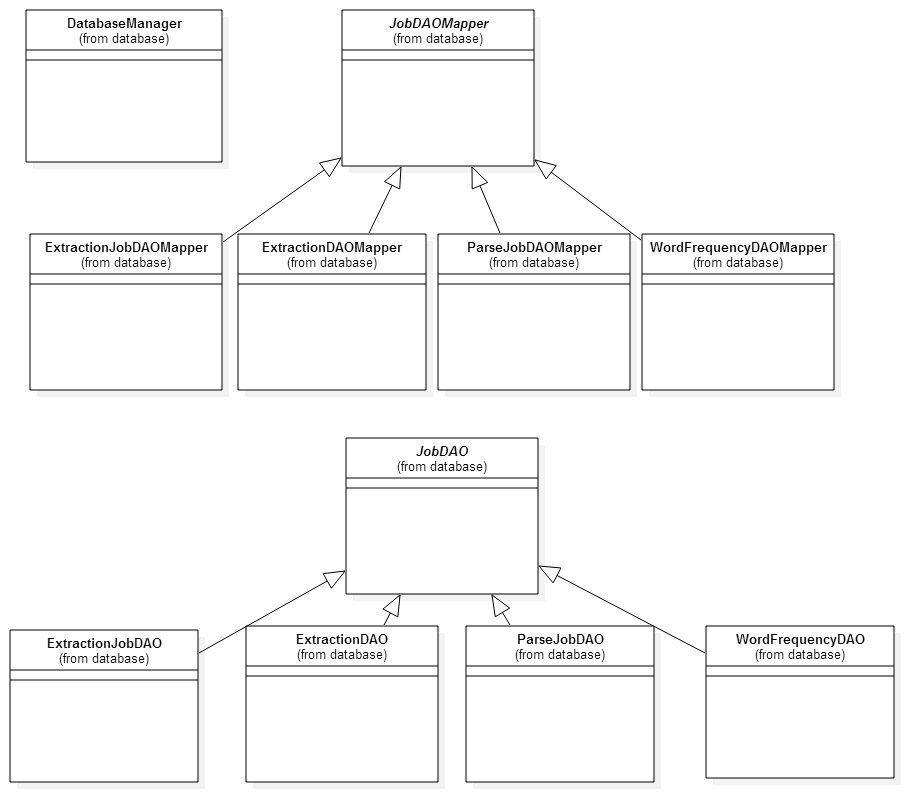
Figure 3
The database package can be found under the database package from the root directory, src/com/webscraper/services/database.
DatabaseManager is a singleton which handles initializing the database driver via the MySQL connector bridge. DatabaseManager also contains the configuration information for the database. In the future, we can offload the configuration information to a local script with some encryption so that we hide the sensitive information regarding the DB. We could also use an authentication protocol with a registered profile on an internal server.
The other classes in the database package implement a Data Access Object pattern for mapping between the relational store of records in the DB to an object model to be used in an application. DAOs can represent one to one mappings between a DAO and a table in the database. DAOs are the model of the data and are simply Plain Old Java Objects (POJOs) without any business logic. The only methods the DAOs have are simply getter and setters for the specific member variables. The JobDAO is a base class for all other DAOs and contains the primary key and the date. The ExtractionJobDAO, ExtractionDAO, ParseJobDAO, and WordFrequencyDAO all represent their respective database tables, ExtractionJobTable, ExtractionTable, ParseJobTable, and WordFrequencyTable.
Mapper classes act as controller logic which either retrieve DAOs or run some CRUD action on the database with DAOs passed in. JobDAOMapper is the base class for all other mappers, and contains the begin and end points of every DB transaction, startConnection() and endConnection(), respectively. The other mapper classes, ExtractionJobDAOMapper, ExtractionDAOMapper, ParseJobDAOMapper, and WordFrequencyDAOMapper map to their corresponding table.
An example of how easy the process is for adding a record to the DB, the following code snippet demonstrates the process:
ExtractionJobDAO dao = new ExtractionJobDAO("www.yahoo.com", false);
ExtractionJobDAOMapper _extractionMapper = new ExtractionJobDAOMapper();
_extractionMapper.addDAO(dao);
Component Design
There are four primary applications, ExtractionJobQueue.java, ExtractionService.java, ParsingJobQueue.java, and ParsingService.java, which can found under the services package from the root directory, src/com/webscraper/services. Each of these applications is standalone, and in their first implementation, will poll for work, and when finished or complete, will sleep for a certain amount of time (currently in minutes). After the sleep time has expired, the applications will check for work again, and continue the cycle. This design allows for easy scalability as each of these applications can be scaled either by replicating and running multiple instances of the same application, or even adding worker threads to each of the applications without affecting the other components. Also, this model helps with redundancy as if one application fails, the failure will not affect the other components. Decoupling the business logic for these discrete, atomic operations by having four separate applications can create a much more robust system.
The first application, ExtractionJobQueue.java, is responsible for checking for new units of work, which in this context means a new URL has been submitted. For now, this application will periodically check a file on disk for the next list of URLs to create jobs for. In the future, we could create a service that accepts jobs via remote procedure calls (RPCs) instead of a file. Once the application has a URL, it will then create a job and populate the webscraper_service_db in the ExtractionJobTable table. A deployment diagram of this application is shown here in Figure 4:
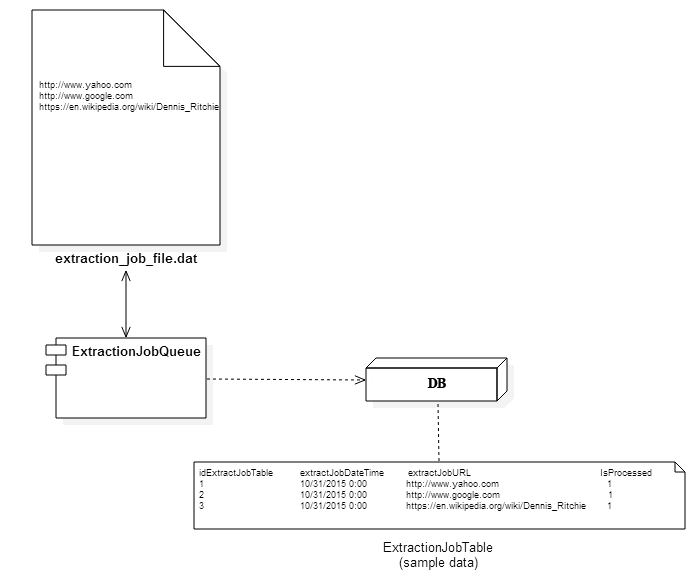
Figure 4
The second application, ExtractionService.java, is responsible for checking for new units of work, which in this context means a new ExtractionJob has been submitted and has not been processed yet. Once the application has a job, it will then process the URL found in the job by parsing the HTML, generated a DOM representation of that HTML, and extract the text found within the tag elements. Finally, the application will create an entry in the webscraper_service_db and populate the ExtractionTable table with the extracted text. A deployment diagram of this application is shown here in Figure 5:
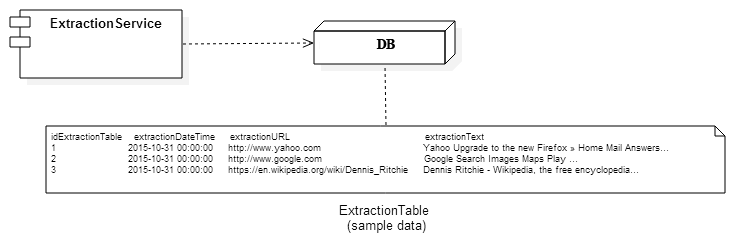
Figure 5
The third application, ParsingJobQueue.java, is responsible for checking for new units of work, which in this context means a valid job is one where ExtractionTable table does not have a corresponding foreign key in the ParseJobTable table. For now, if there isn’t currently a job that has processed an ExtractionTable record, then the record is ripe for a parse job. Once the application has the corresponding extracted text, it will then create a job and populate the webscraper_service_db in the ProcessJobTable table with a foreign key (FK) which points to the primary key (PK) in the ExtractionTable table. A deployment diagram of this application is shown here in Figure 6:
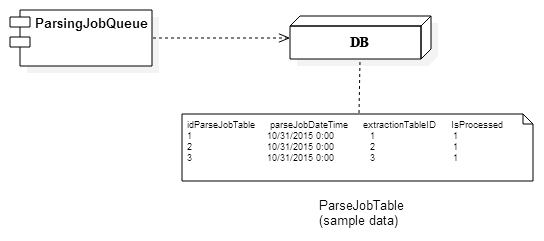
Figure 6
The fourth and final application, ParsingService.java, is responsible for checking for new units of work, which in this context means a new ParseJobTable job has been submitted and has not been processed yet. Once the application has a job, it will then process the extracted text obtained from a query via the foreign key in the job. The extracted text will be tokenized using a regular expression pattern of one or more spaces as the delimiters. The tokenized strings will then be processed in a map as the keys, iterating through all tokens, and checking to see if they already exist in the map. If they do exist in the map, then we increment the value associated with the entry, otherwise we will add the new entry to the map.
NOTE: It is probably a good idea to develop a blacklist of words and/or regular expressions for patterns we can filter out, including special characters that create malformed SQL, or possibly malicious attacks using SQL injection. We could also match words to existing dictionaries to see if there are matches. A sanitation step is definitely important for data integrity.
Finally, the application will create an entry in the webscraper_service_db and populate the WordFrequencyTable table with the appropriate word entries with their corresponding frequency values. We will first try to update the table with the record so that we don’t have duplicate words. If the record does not exist, then we will add it. A deployment diagram of this application is shown here in Figure 7:
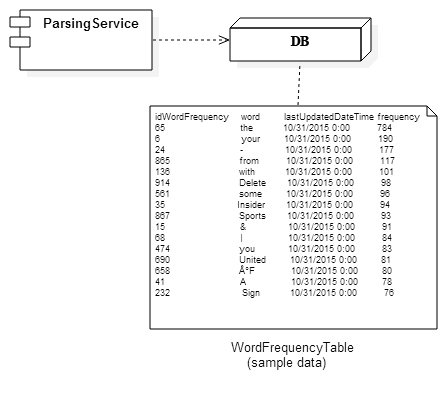
Figure 7
Build and Run Steps
Eclipse:
- Launch the Eclipse executable
- Select your workspace
- In Eclipse, select File | Import
- In the Import dialog, select Maven | Existing Maven Projects, and click Next
- In the Import Maven Projects dialog, select WebScraperService as the root directory (from the source) (It should find the pom.xml from the root)
- Click Finish
- Once the project loads, you can run the applications in order by selecting each application source file, right clicking, and selecting Run As | Java Application
- ExtractionJobQueue.java
- ExtractionService.java
- ParsingJobQueue.java
- ParsingService.java
In order to build and run from the command line, I would need to install a separate Maven install and configure. If there is an issue running the applications from Eclipse, and there is a preference for command line build, this can be added.
Future Work
- Need to evaluate other alternatives to JSoup just to verify there are no better choices.
- Need to create test cases for large datasets. If performance becomes an issue as these records increase, we may need to look into creating views for faster lookups.
- If there are other performance problems, then there may be a need to have stored procedures instead of the current approach of using prepared statements.
- Currently, autocommit is configured for the MySQL database. In the future, we may want to batch large jobs in one task for efficiency, but we will need to commit manually, including rollback logic, and maybe even use savepoints to prevent the entire batch commit from failing.
- Persist configuration information to a local script with some encryption so that we hide the sensitive information regarding the DB.
- Create a service that accepts ExtractionJobTable jobs via remote procedure calls (RPCs) instead of a file.
- Develop a blacklist of words and/or regular expressions for patterns we can filter out, including special characters that create malformed SQL, or possibly malicious attack with SQL injection.
- Need to flesh out the Mapper classes with add, update, and delete. Also need to create more find() type methods for common queries.
References
- http://jsoup.org/cookbook/extracting-data/dom-navigation
- http://web-harvest.sourceforge.net/overview.php
- http://simplescrape.sourceforge.net/
- https://ecs.victoria.ac.nz/foswiki/pub/Courses/COMP423_2015T1/LectureSchedule/WebScrapping.pdf
- https://www.packtpub.com/books/content/creating-sample-web-scraper
- http://www.geog.leeds.ac.uk/courses/other/programming/practicals/general/web/scraping-intro/2.html
- http://stackoverflow.com/questions/13506832/what-is-the-mysql-varchar-max-size
- https://dev.mysql.com/doc/workbench/en/wb-getting-started-tutorial-creating-a-model.html
- http://stackoverflow.com/questions/1827063/mysql-error-key-specification-without-a-key-length
- http://stackoverflow.com/questions/8620127/maven-in-eclipse-step-by-step-installation
- http://stackoverflow.com/questions/2037188/how-to-configure-eclipse-build-path-to-use-maven-dependencies
- http://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.37